SecureLLM User Guide¶
SecureLLM is your organization’s secure gateway to AI. Instead of everyone connecting directly to different AI services, all requests go through one central hub that your team controls. This means consistent access, cost tracking, and safety guardrails — without you needing to manage separate accounts or API keys for every AI provider.
Logging In¶
Production: SecureLLM uses your company’s single sign-on (SSO). Navigate to the app URL and you are logged in automatically using your existing credentials — no separate account or password needed.
Development mode: A /login page is shown where you enter your email address to sign in.
For All Users¶
Once logged in, you will see a sidebar with four pages: Dashboard, API Keys, Models, and Usage.
Dashboard¶
The Dashboard gives you a snapshot of your AI usage at a glance.
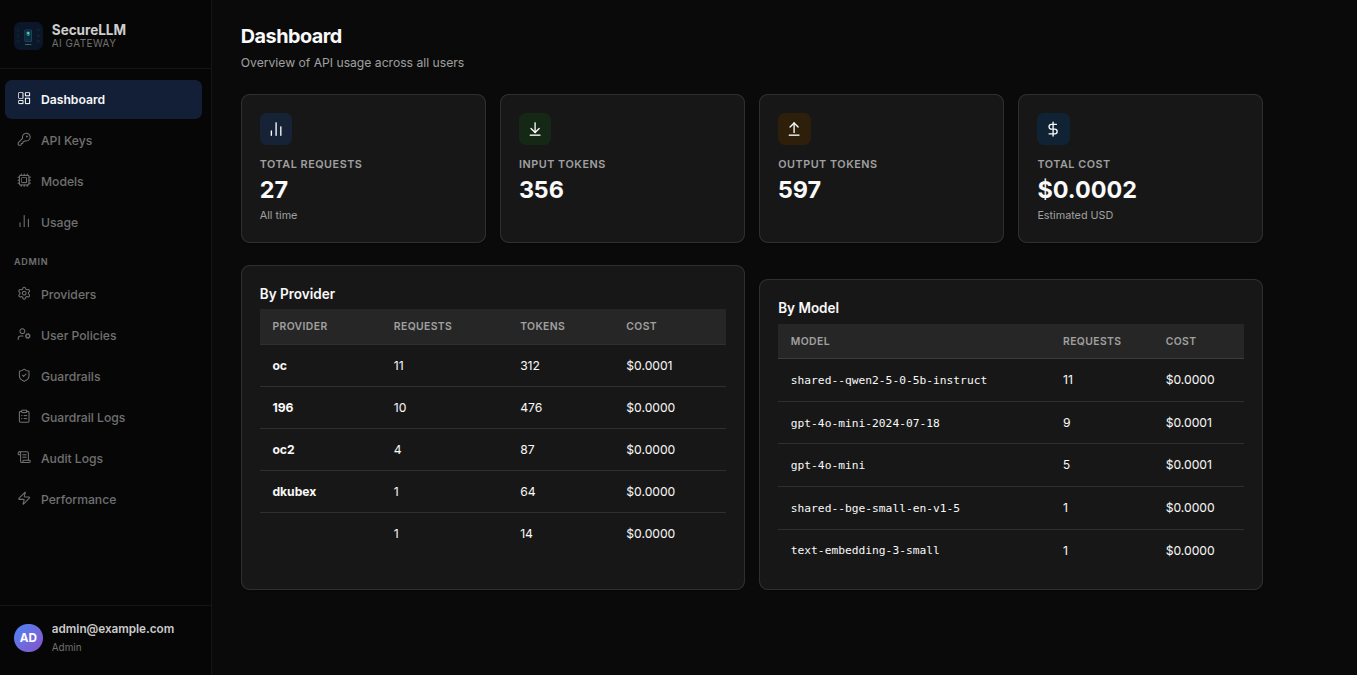
Total Requests — how many AI calls you have made
Input / Output Tokens — a measure of how much text was sent and received (tokens ≈ words)
Total Cost — estimated spend based on your requests
By Provider / By Model — tables showing which AI services and models you used most
Note: If you have admin access, the Dashboard shows usage for your entire organization, not just your own.
API Keys¶
An API key is like a password that lets an application (a script, a tool, or an IDE plugin) talk to SecureLLM on your behalf. You create keys here and paste them into whichever tool needs them.
Creating a key:
Click API Keys in the sidebar.
Click Create Key.
Enter a descriptive name (e.g.,
my-vscode-pluginordata-pipeline).Click Create.
Copy the key immediately — it is only shown once. Store it somewhere safe (a password manager or
.envfile).
Revoking a key:
Find the key in your list.
Click Revoke.
Confirm the action.
Tip: If you suspect a key has been leaked or is no longer needed, revoke it right away. Revoking a key instantly stops any further requests made with it.
Models¶
The Models page lists every AI model available to you through SecureLLM.
Use the search bar to find a specific model by name.
Use the Provider and Category filters to narrow the list (e.g., Chat, Reasoning, Embedding).
Click the copy icon next to a model name to copy its identifier — paste this directly into your code or tool.
Note: If an admin has restricted your access, you will only see the models and providers your organization has made available to you.
Usage (My Requests)¶
The Usage page shows your request history — everything you or your keys have sent to SecureLLM.
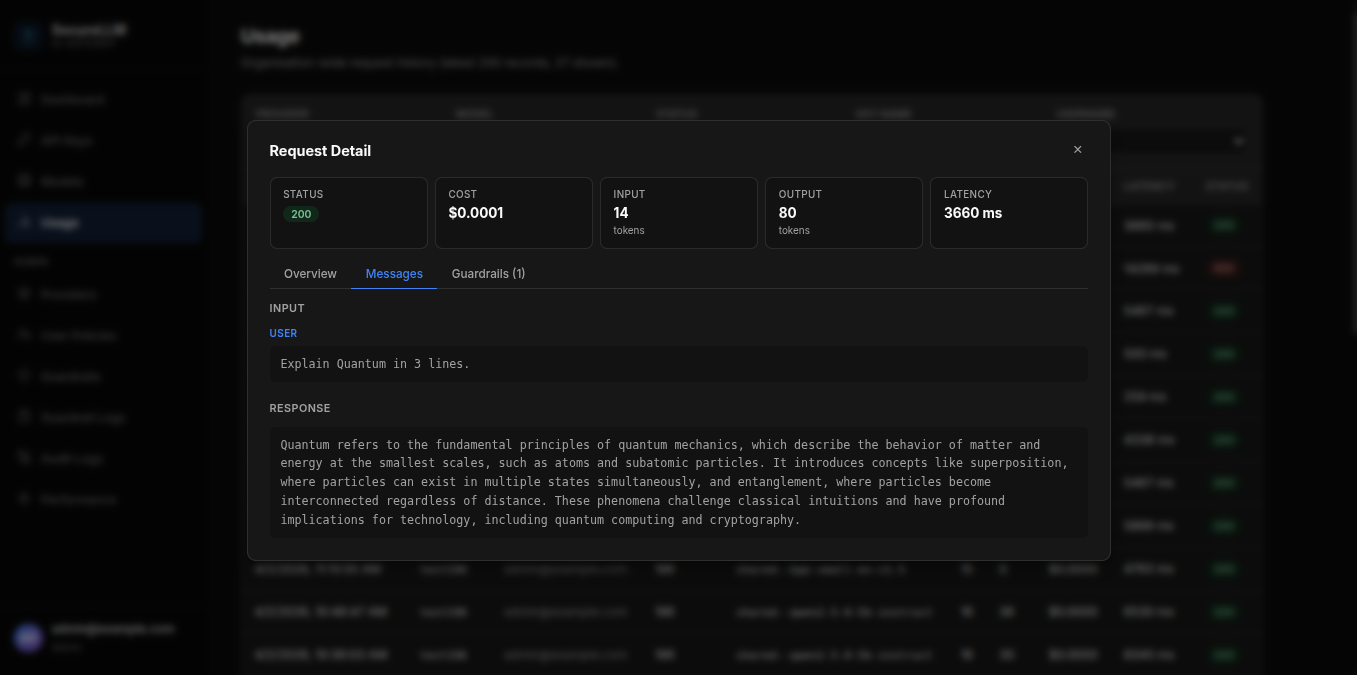
Use the filters at the top to narrow by provider, model, status, or API key name.
Click any row to open the Request Detail panel, which shows:
The exact messages sent and the AI’s response
Request status, cost, token counts, and latency
Any guardrail events triggered by that request
For Administrators¶
Note: Admin pages are only visible if your account has been granted admin access. Contact your SecureLLM administrator if you believe you should have admin rights.
Admins see all four user pages (with organization-wide data) plus six additional pages: Providers, Users, Guardrails, Guardrail Logs, Audit Logs, and Performance.
Dashboard (Admin View)¶
Identical to the user dashboard, but all numbers reflect the entire organization — every user’s requests, tokens, and costs. Use this to monitor overall AI spend and identify which teams or models drive the most usage.
Providers¶
Providers are the AI services SecureLLM connects to (e.g., OpenAI, Anthropic, or your organization’s own AI deployment).
Adding a provider:
Click Providers → Add Provider.
Select the provider type from the dropdown.
Enter the provider’s API Key and, if needed, a custom Base URL.
Optionally list Allowed Models (leave blank to allow all models from this provider).
Click Save.
Enabling / disabling a provider:
Use the toggle switch on each provider card. Disabling pauses routing to that provider without losing its configuration — useful for maintenance or cost control. Only delete a provider when you are certain it will never be used again.
Users¶
The Users page lets you set access policies for individual users — controlling which providers and models each person can use.
Adding a restriction:
Click Users → Add Restriction.
Enter the user’s email or username.
Specify Allowed Providers and/or Allowed Models (comma-separated).
Click Save.
To remove all restrictions from a user (giving them full access), click Remove next to their policy.
Guardrails¶
Guardrails are automatic safety filters that inspect AI requests and responses before they reach the AI or your users.
Three guardrail types:
Type |
What it does |
|---|---|
Content Filter |
Blocks or masks sensitive content — credit card numbers, passwords, PII (names, phone numbers, etc.) |
Prompt Injection |
Detects attempts to manipulate the AI into ignoring its instructions (jailbreak attempts) |
Custom |
Advanced: accepts a raw JSON configuration for organization-specific rules |
Enabling or disabling a guardrail: Use the toggle switch on each guardrail card. Changes take effect immediately for all new requests.
Testing a guardrail:
Click the Test Guardrails tab.
Select one or more guardrails to test.
Paste sample text into the input box.
Click Run Test.
Results show whether the guardrail triggered, what action it took (block / mask / warn), and how long it took to run.
Guardrail Logs¶
Every time a guardrail evaluates a request, it writes a log entry here.
Filter by guardrail name or trigger status (triggered / not triggered).
The summary bar shows total events, how many triggered, and the overall pass rate.
Click any row to see the exact text that was flagged and the action taken.
Use this page to verify that your guardrails are catching what they should — and not over-blocking legitimate requests.
Audit Logs¶
Audit Logs record every administrative action taken in SecureLLM: who created or revoked a key, who changed a provider, who updated a user policy — with timestamps and IP addresses.
Filter by actor (admin’s email) or action type (e.g.,
create_key,revoke_key,update_provider).Use this page for compliance reviews or to investigate unexpected changes.
Performance¶
The Performance page shows how the gateway itself is behaving.
Uptime — how long SecureLLM has been running since last restart
Total Requests / 5xx Errors — overall traffic and error counts
Latency by Endpoint — P50, P95, and P99 response times per API endpoint
Tip: P95 latency is the response time that 95% of requests fall under. A spike here usually means a specific provider is slow, not that SecureLLM itself is the bottleneck.
Quick Reference¶
Page |
Regular User |
Administrator |
|---|---|---|
Dashboard |
Own usage stats |
Organization-wide stats |
API Keys |
Create / revoke own keys |
Create / revoke / restrict any key |
Models |
Browse available models |
Browse + manually refresh list |
Usage |
Own request history |
All users’ request history |
Providers |
— |
Add / edit / enable / disable |
Users |
— |
Set per-user access policies |
Guardrails |
— |
Configure, toggle, and test |
Guardrail Logs |
— |
View and filter |
Audit Logs |
— |
View and filter |
Performance |
— |
View gateway metrics |